The prevalence of errors that slip past peer-review and make it into the scientific literature has recently been a topic of interest. In particular, the issues of miscalculated statistical values, URL decay, and errors in biological database IDs and gene names. Science is facing some unprecedented challenges in maintaining the fidelity of the published record. First, the number of published papers per year growing exponentially. Second, the size of each paper, on average, is also increasing, often in the form of supplementary information. Third, the number of potential reviewers is not increasing, meaning less time and attention per paper.
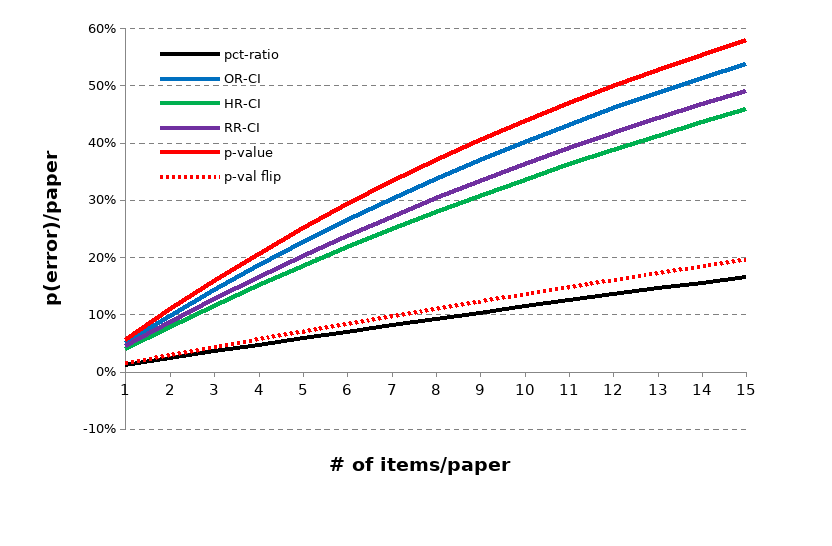
Figure: The probability of an error existing within a paper rises with the number of reported items per paper.
Using algorithms can alleviate some of these pressures very cost-effectively, particularly those that involve recalculations, cross-checking reported values, and looking for trends of concern (e.g., plagiarism, excessive self-citation, etc). We are developing a service called PubQC to help automate certain aspects of peer-review. Just as spell-checkers were once considered novel but are ubiquitous today, we envision scientific error-checking will become an important and integral component in the future.